On 08.08.2020 (Saturday) and 09.08.2020 (Sunday) the first AI for People Workshop will be held. The event will be held online and is entirely free. Register here.
AI for People was born out of the idea of shaping Artificial Intelligent technology around human and societal needs. We believe that technology should respect the anthropocentric principle. It should be at the service of people, not vice-versa. In order to foster this idea, we need to narrow the gap between civil society and technical experts. This gap is one in knowledge, in action and in tools for change.
In this spirit, we want to share our knowledge through a hands-on workshop with everyone. We are glad to announce 7 speakers offering talks of a diversity of topics about and around Artificial Intelligence. There are 2 basic courses which require little to no programming experience, 4 advanced courses with varying degree of technical depth and one invited speaker.
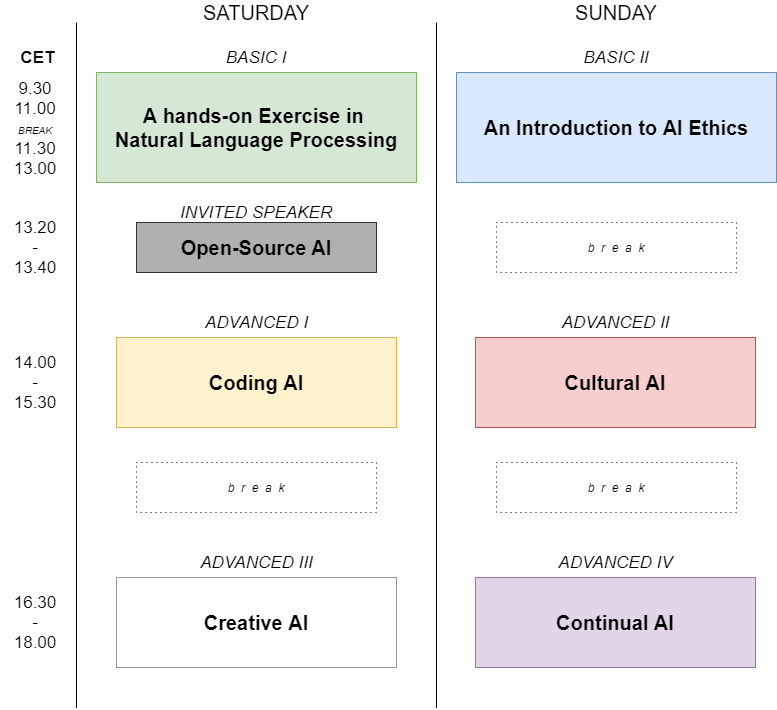
The Schedule:
All times are CET (Central European Time)
The Topics and Speaker:
A hands-on Exercise in Natural Language Processing. The lecturer Philipp Wicke will give a brief introduction to Natural Language Processing (NLP). This lecture is very practice-oriented and Philipp will show an example of topic modeling on real data. More …Introduction to AI Ethics. Our chair Marta Ziosi will provide a broad introduction the topics ethically relevant to AI development. Whether you have a technical or social science background, this course will present you with the trade-offs that technology faces society with and it will provide you with the conceptual tools relevant to the field of AI ethics. More …Open-Source AI. Our invited speaker Dr. Ibrahim Haddad, Executive Director of the LF AI Foundation, will talk about open source AI. More …Coding AI. The lecturer Kevin Trebing will give an introduction on how to create AI applications. For this, you will learn the basics of PyTorch, one of the biggest AI frameworks next to TensorFlow. More …Cultural AI. Maurice Jones will outline how the meaning of AI as a technology is socially constructed and which role cultural factors play in this process. He will give a practical example on how different cultures create different meanings surrounding technologies. More …Creative AI. The lecturer Gabriele Graffieti will give an introduction on creative AI, what it means for an artificial intelligence to be creative and how to instill creativity into the training process. In this lecture we’ll cover in detail generative models and in particular Generative Adversarial Networks. More …Continual AI. The lecturer Vincenzo Lomonaco will give a brief introduction to the topic of Continual Learning for AI. This lecture is very practice-oriented and based on a slides, and runnable code on Google Colaboratory. You will be able to code and play alongside the lecture in order to acquire the basic knowledge and skills. More …
The course is free for everyone, yet we ask you to register in advance. As a non-profit organisation all of our work and effort is voluntary. If you like the workshop, we suggest a donation of 15€ for the entire workshop (aiforpeople.org/supporters).
Attendance is limited through the virtual classroom and entry is based on first-registered-first-served, therefore we ask you to register as soon as possible here: REGISTRATION
If you have any questions, feel free to contact us at: aiapplications@46.101.110.35
1st AI for People Workshop was originally published in AI for People on Medium, where people are continuing the conversation by highlighting and responding to this story.
On 08.08.2020 (Saturday) and 09.08.2020 (Sunday) the first AI for People Workshop will be held. The event will be held online and is entirely free. Register here.
AI for People was born out of the idea of shaping Artificial Intelligent technology around human and societal needs. We believe that technology should respect the anthropocentric principle. It should be at the service of people, not vice-versa. In order to foster this idea, we need to narrow the gap between civil society and technical experts. This gap is one in knowledge, in action and in tools for change.
In this spirit, we want to share our knowledge through a hands-on workshop with everyone. We are glad to announce 7 speakers offering talks of a diversity of topics about and around Artificial Intelligence. There are 2 basic courses which require little to no programming experience, 4 advanced courses with varying degree of technical depth and one invited speaker.
The Schedule:
All times are CET (Central European Time)
The Topics and Speaker:
A hands-on Exercise in Natural Language Processing. The lecturer Philipp Wicke will give a brief introduction to Natural Language Processing (NLP). This lecture is very practice-oriented and Philipp will show an example of topic modeling on real data. More …Introduction to AI Ethics. Our chair Marta Ziosi will provide a broad introduction the topics ethically relevant to AI development. Whether you have a technical or social science background, this course will present you with the trade-offs that technology faces society with and it will provide you with the conceptual tools relevant to the field of AI ethics. More …Open-Source AI. Our invited speaker Dr. Ibrahim Haddad, Executive Director of the LF AI Foundation, will talk about open source AI. More …Coding AI. The lecturer Kevin Trebing will give an introduction on how to create AI applications. For this, you will learn the basics of PyTorch, one of the biggest AI frameworks next to TensorFlow. More …Cultural AI. Maurice Jones will outline how the meaning of AI as a technology is socially constructed and which role cultural factors play in this process. He will give a practical example on how different cultures create different meanings surrounding technologies. More …Creative AI. The lecturer Gabriele Graffieti will give an introduction on creative AI, what it means for an artificial intelligence to be creative and how to instill creativity into the training process. In this lecture we’ll cover in detail generative models and in particular Generative Adversarial Networks. More …Continual AI. The lecturer Vincenzo Lomonaco will give a brief introduction to the topic of Continual Learning for AI. This lecture is very practice-oriented and based on a slides, and runnable code on Google Colaboratory. You will be able to code and play alongside the lecture in order to acquire the basic knowledge and skills. More …
The course is free for everyone, yet we ask you to register in advance. As a non-profit organisation all of our work and effort is voluntary. If you like the workshop, we suggest a donation of 15€ for the entire workshop (aiforpeople.org/supporters).
Attendance is limited through the virtual classroom and entry is based on first-registered-first-served, therefore we ask you to register as soon as possible here: REGISTRATION
If you have any questions, feel free to contact us at: aiapplications@46.101.110.35
1st AI for People Workshop was originally published in AI for People on Medium, where people are continuing the conversation by highlighting and responding to this story.
Leading researchers of the field of Artificial Intelligence met to discuss the future of (human/artificial) intelligence and its implications on society in the first Interdisciplinary Summer School on Artificial Intelligence, from the 5th to the 7th of June in Vila Nova da Cerveira, Portugal. Members of the AI for People association were present to gain a perspective on current trends in AI that reflect on societal benefits and problems. In the following article, we provide a brief overview of the topics discussed in the talks at the conference and highlight implications for societal advantages or disadvantages of AI progress. Notably, not all the talks have been summarised as we focused only on those that were considered relatable to the attending members of AI for People.
Computational Creativity
Tony Veale from the Creative Language Systems Group at UCD, provides an overview of Computational Creativity (CC). This research domain aims to create machines that create meaning. Creativity is thought of as the final frontier in artificial intelligence research [1]. Creative computer systems are already a reality in our society, whether it is generated fake-news, computer-generated art or music. But are those systems truly creative or mere generative systems? The CC domain does not aim by all means to replace artists and writers with machines, but tries to develop tools which can be used in a co-creative process. Such semi-autonomous creative systems can provide computation power to explore the creative space that would not be accessible to the creators on their own. Prof. Veale’s battery of twitter-bots aims to provoke the creation of interaction within the vibrant and dynamic twitter community [2]. The holy grail of CC — developing truly creative systems, capable of criticising, explaining and creating their own masterpieces — is still considered at debatable reach.
Machines that Create Meaning (on Twitter). More creative Twitterbots at afflatus.ucd.ie.
Implications: We see Artificial Intelligence as something logical, reasonable and efficient. Often, we associate its influence with economy and technology. We might overlook that the domain of creativity, which is in its core a developing society within its culture, art and communication, equally affected by AI. We need to become aware of this influence, which works on the one hand in favour of the creative human potential by providing powerful tools that can help us develop new ideas. On the other hand, there is the potential of underestimating this creative influence and falling for fake-news and alike. The former is the benevolent use of CC, whereas the latter is the malicious (ab)use of CC.
Machine Learning in History of Science
Jochen Büttner from the MPIWG Berlin presented new tools for a long-established discipline: Using machine learning approaches for corpus research in the history of science. Büttner presents the starting point as the extraction of knowledge from the analysis of an ancient literature corpus. Conventional methods, e.g. manual identification of similar illustrations among different documents, are highly time-consuming and seen as impractical. However, machine learning techniques provide a solution to such tasks.
Büttner explained how different techniques are being utilised to detect illustrations on digitised books and identify clusters of illustration, based on the use of the same woodblocks in the printing process (shared between printers or passed on).
Implications: The research provides an interesting example of how one research field (history of science) can greatly benefit from another (artificial intelligence). With only 6 months of AI experience Prof. Büttner can achieve results that otherwise would be years of effort. Yet, from an AI perspective, the implementation is rather naive. The resulting divergence of abstract machine learning research with actual applications in other domains is clear as specialised algorithms could be used to yield better results. Challenges addressed by the talk are the rapid pace of development in ML, which already seems to be overwhelming when specialising only on Machine Learning. Overall, ML requires a rather high demand in mathematical computational understanding, which makes it even harder for foreign domains to gain access. Therefore, it is key to provide adequate educational paths for everyone and encourage the application of AI by establishing adequate publication formats, which will in return foster interdisciplinary dialogue.
Artificial Intelligence Engineering: A Critical View
The industry talk had been given by Paulo Gomes Head of AI at Critical Software. Gomes provides insights from someone who has worked for years in research switching to industry. The company is involved in several projects that use Machine Learning: identification of anomalous behaviour in vessels (navigation problems, drug traffic, illegal fishing), prediction of phone signal usage to prevent mobile network shutdowns, optimization of car manufacturing energy consumption or even decision making in stress situations in the military context. The variety of addressed domains shows the range of involvement of AI in our ‘technologised’ society.
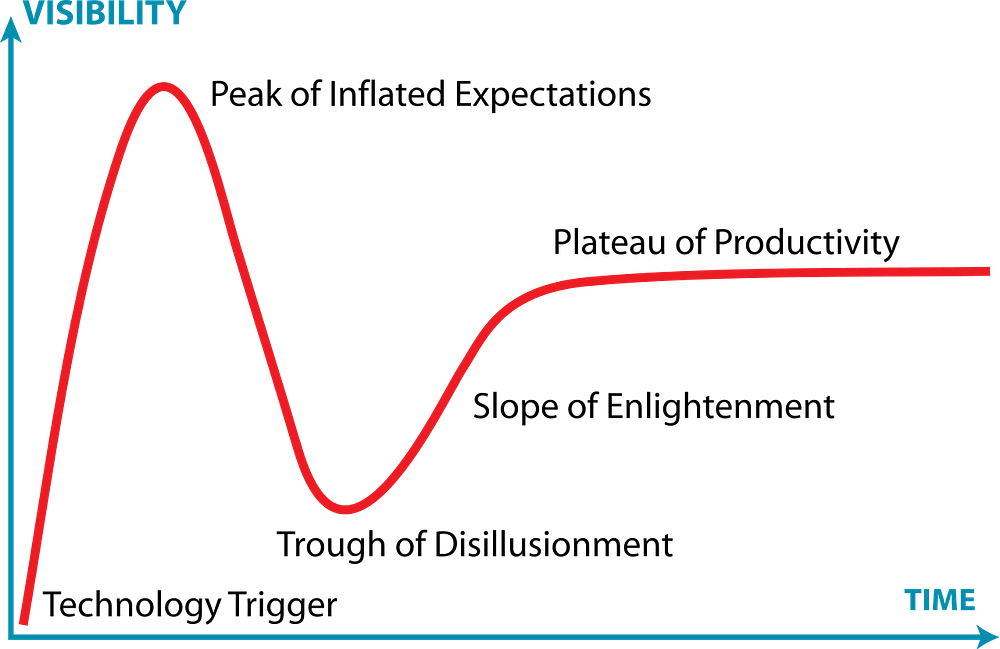
Implications: The talk also addresses the critical gap between what companies promise and what is actually possible with AI. This gap is not only bad to the economy, but directly harmful to people. As AI will grow, the expectations have already grown much higher than what can be achieved in neither research nor industry. The AI-hype about the massive leaps in technology due to recent developments in deep learning are somewhat justified, triggering a “New Arms Race for AI” [3] between the USA, Russia and China. The talk points out that this technological bump fits into the scheme of the hype cycle for emerging technologies with Deep Learning as the technology trigger (see image).
The hype cycle as described by the American research, advisory and information technology firm Gartner (diagram CC BY-SA 3.0).
Suddenly, every company needs to open up an AI department even though there are too few people with the actual experience in the field. A wave of job quitting and career swapping is currently being observed. Nonetheless, in most cases people find themselves with little field experience in a company that has even less — low knowledge growth and lack of appreciation due to little understanding from the company’s side. These people might end up jumping in front of rather than on top of the AI hype train.
Why superintelligent AI will never exist
This talk was given by Luc Steels from VUB Artificial Intelligence Lab (now at the evolutionary biology department at Pompeu Fabra University). In a similar fashion to the previous talk, Steels outlines the rise of AI technologies in research, economy and politics. The cycle is described in a somewhat different way and can be found in various other phenomena: Climate change has been discussed for decades, but it had been given very little actual attention in politics and economics. It is only when people are faced with the immediate consequences that politics and economics start to pick it up. In the race for AI technology, we can observe this first underestimation by a lack of development, i.e. for a long time AI struggled with its establishment in the academic world and found little attention in economy. Now, we are facing an overestimation in which everyone is creating higher and higher expectations. Why is it, that the promised superintelligent AI will not exist? Here are a few examples and implications from Steels:
Most Deep Learning systems are very dataset-specific and task-specific. For example, systems that are trained to recognize dogs, fail to recognize other animals or dog images that are turned upside-down. The features learned by the algorithm are irrelevant when it comes to human categorization of reality.
It is said that these problems can be overcome by more data. But many of those problems are due to the distribution and the probability within the data and those will not change. That is, those systems do not learn global context, even if presented with more data.
Language systems can be trained without a task and can be provided massive amounts of context. Yet, language is a dynamic, evolving system that changes strongly over time and context. Therefore, language models would lose their validity quickly unless they are retrained on a regular basis, which is a ridiculously effortful computation.
“A deep-learning system doesn’t have any explanatory power, the more powerful the deep-learning system becomes, the more opaque it can become. As more features are extracted, the diagnosis becomes increasingly accurate. Why these features were extracted out of millions of other features, however, remains an unanswerable question.”
Geoffrey Hinton, computer scientist at the University of Toronto — founding father of neural networks
The systems learn from our data, not our knowledge. Therefore, in some cases these systems do not apply any sort of common sense and take our biases into their models. For example, Microsoft’s Tay chatbot that starting spreading anti-semitism after only a few hours online [4].
Reinforcement learning algorithms are implemented to optimize the traffic on a web-page and not to provide content. Consequently, click-baits are more valuable to the algorithm than useful information.
Conclusion
This summer school was the first of its kind, a collaboration of the AI associations from Spain and Portugal. Despite the reduced number of participants and the lack of female speakers, this first interdisciplinary platform for the AI community provided a basic discussion about the implications of AI and its future. More people should be educated about the illusionary expectations created by the AI hype in order to prevent any damage to research and society. The author would like to thank João M. Cunha and Matteo Fabbri for their contributions to this article.
References:
[1] Colton, Simon, and Geraint A. Wiggins. “Computational creativity: The final frontier?.” Ecai. Vol. 12. 2012.
[2] Veale, Tony, and Mike Cook. Twitterbots: Making Machines that Make Meaning. MIT Press, 2018.
[3] Barnes, Julian E., and Josh Chin. “The New Arms Race in AI.” The Wall Street Journal 2 (2018).
[4] Wolf, Marty J., K. Miller, and Frances S. Grodzinsky. “Why we should have seen that coming: comments on Microsoft’s tay experiment, and wider implications.” ACM SIGCAS Computers and Society 47.3 (2017): 54–64.
Do we really understand responsibilities in Artificial Intelligence or are we confusing terms and technology in the debate? (Photo credit: https://flic.kr/p/27pq9bw)
This blog post has not been written by an AI. This blog post has been written by a human intelligence pursuing a PhD in Artificial Intelligence. Although, the first sentence seems to be trivial it might not be so in the near future. If we can no longer distinguish a machine from a human during a phone call conversation, as Google Duplex has promised, we should start to be suspicious about textual content on the web. Bots are already made responsible for 24% of all tweets on Twitter. Who is responsible for all this spam?
But really, this blog post has not been written by an AI — trust me. If it were, it would be much smarter, more eloquent and intelligent, because eventually AI systems will make better decisions than humans. And the whole argument about responsible AI, is more of an argument about how we define better in the previous sentence. But first let’s point out, that the ongoing discussion about responsible AI often conflates at least two levels of understanding algorithms:
Artificial Intelligence in the sense of machine learning applications
General Artificial Intelligence in the sense of an above-human-intelligence system
This blog post does not aim to blur the line between humans and machines, neither does it aim to provide answers to ethical questions that arise from artificial intelligence. In fact, this blog post simply tries to contrast the conflated layers of AI responsibility and presents a few contemporary approaches at either of those layers.
Artificial Intelligence in the sense of machine learning applications
In recent years, we have definitely reached the first level of AI that does already present us with an ethical dilemma in a variety of applications: Autonomous cars, automated manufacturing and chatbots. Who is responsible for the accident by self-driving car? Can a car decide in face of a moral dilemma that even humans struggle to agree on? How can technical advances can be combined with education programs (human resource development) to help workers practice new sophisticated skills so as not to lose their jobs? Do we need to declare online identities (is it a person or a bot?). How do we control for manipulation of emotions through social bots?
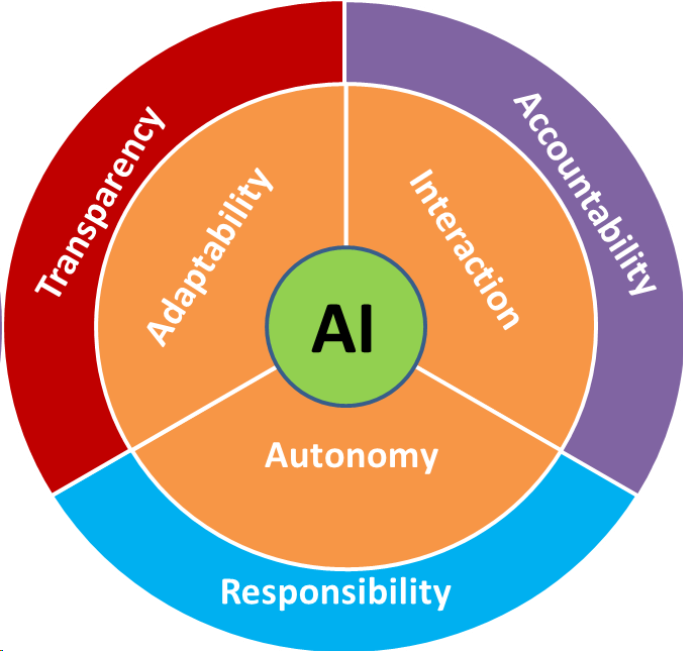
These are all questions that we are already facing. The artificial intelligence that gives rise to these questions is a controllable system, that means that its human creator (the programmer, company or government) can decide how the algorithm should be designed such that the resulting behaviour abides whatever rules follow from the answers to the given questions. The responsibility is therefore with the human. The same way we sell hammers, which can be used as a tool or abused as a weapon, we are not responsible for malicious abuse of AI systems. Whether for good or bad, these AI systems show adaptability, interaction and autonomy, which can be layered with their respective confines.
Autonomy has to act within the bounds of responsibility, which includes the chain of responsible actors: If we give full autonomy to a system, we cannot take responsibility for its actions, but as we do not have fully autonomous systems yet, the responsibility is with the programmers followed by some supervision, which normally follows company standards. Within this well-established chain of responsibility that is in place in most industrial companies, we need to locate the responsibilities for AI system with respect to their degree of autonomy. The other two properties, adaptability and interaction, do directly contribute to the responsibility we can have over a system. If we allow full interaction of the system, we lose accountability, hence we give away responsibility again. Accountability cannot only be about the algorithms, but about the interaction must provide an explanation and justification to be accountable and consequently responsible. Each of these values is more than just a difficult balancing act, they pose intricate challenges in their very definition. Consider explainability of accountable AI, we already see the surge of an entire field called XAI (Explainable Artificial Intelligence). Nonetheless, we cannot simply start explaining AI algorithms on the basis of their code for everyone, firstly we need to come up with a feasible level of an explanation. Do we make the code open-source and leave the explanation to the user? Do we provide security labels? Can we define quality standards for AI?
The latter has been suggested by the High-Level Expert Group on AI of the European AI Alliance. This group of 52 experts includes engineers, researchers, economists, lawyers and philosophers from an academic, non-academic, corporate and non-corporate institutions. The first draft on Ethics Guidelines For Trustworthy AI proposes guiding principles, investment and policy strategies and in particular advises on how to use AI to build an impact in Europe by leveraging Europe’s enablers of AI.
On the one hand, the challenges seem to be broad and coming up with ethics guidelines that encompass all possible scenarios appears to be a daunting task. On the other hand, all of these questions are not new to us. Aviation has a thorough and practicable set of guidelines, laws and regulations that allow us to trust systems which already are mostly autonomous and yet we do not ask for an explanation of its autopilot software. We cannot simply transfer those rules for all autonomous applications, but we should concern ourselves with the importance of those guidelines and not condemn the task.
General Artificial Intelligence in the sense of an above-human-intelligence system
In the previous discussion, we have seen that the problems that arise from the first level of AI systems does impact us today and that we are dealing with those problems one way or the other. The discussion should be different if we talk about General Artificial Intelligence. Here, we assume that at some point the computing power of a machine supersedes not only the computing power of a human brain (which is already the case), but gives rise to an intelligence that supersedes human intelligence. At this point, it has been argued that this will trigger an unprecedented jump in technological growth, resulting in incalculable changes to human civilization — the so-called technological singularity.
In this scenario, we no longer deal with a tractable algorithm, as the super-intelligence will be capable of rewriting any sort of rule or guideline it deems to be trivial. There would be no way of preventing the system to breach any security barrier that has been constructed using human intelligence. There are many scenarios which predict that such an intelligence will eventually get rid of humans or will enslave mankind (see Bostrom’s Superintelligence or The Wachowskis’ Matrix Trilogy). But there is also a surge of serious research institutions, which aim to argue for alternative scenarios and how we can align such an AI system with our values. We see that this second level of AI has much larger consequences with questions that can only be based on theoretical assumptions, rather than pragmatic guidelines or implementations.
An issue that arises from the conflation of the two layers is that people tend to mistrust a self-driving car, as they attribute some form of general intelligence to the system that is not (yet) there. Currently, autonomous self-driving cars only avoid obstacles and are not even aware of the type of object (man, child, dog). Furthermore, all the apocalyptic scenarios contain the same sort of fallacy, they argue using human logic. We simply cannot conceive a logic that would supersede our cognition. Any sort of ethical principle, moral guideline or logical conclusion we want to attribute the AI with, has been derived from thousands of years of human reasoning. A super-intelligent system might therefore evolve this reasoning within a split second to a degree of which it would takes us another thousands of years understanding this step. Therefore, any sort of imagination we have about the future past the point of a super-intelligence is as imaginative as religious imaginations. Interestingly, this conflation of thoughts has lead to the founding of “The Church of Artificial Intelligence”.
Responsibility at both levels
My responsibility as an AI research is to educate people about the technology that they are using and the technology that they will be facing. In case of technology that is already in place, we have to disentangle the notion of Artificial Intelligence as an uncontrollable super-power, which will overtake humanity. As pointed out, the responsibility for responsible AI is with the governments, institutions and programmers. The former need to set guidelines and make sure that they are being followed, the latter two need to follow them. At this stage, it is all about the people to create the rules that they want the AI to follow.
Artificial intelligence is happening and it will not stop merging with our society. It is probably the strongest change of civilization since the invention of the steam engine. On the one hand, the industrial revolution lead to great progress and wealth for most of humankind. On the other hand, it lead to great destruction of our environment, climate and planet. These were consequence we did not anticipate or were willing to accept, consequences which are leading us to the brink of our own extinction if no counter-action will be taken. Similar will be true for the advent of AI that we are currently witnessing. It can lead to great benefits, wealth and progress for most of the technological world, but we are responsible that the consequence are not pushing us over the brink of extinction. Even though we might not be able to anticipate all the consequences, we as the society have the responsibility to act with caution and thoroughness. To conclude with Spiderman’s Uncle’s words “with great power comes great responsibility”. And as AI might be the greatest and last power to be created by humans, it might be too great of a responsibility or it will be smart enough to be responsible for itself.
Once applied to risk assessment in the criminal justice system, are we deceiving ourselves on the wrong track?
This article questions the current undertakings of the ethical debate surrounding predictive risk assessment in the criminal justice system. In this context, the ethical debate currently revolves around how to engage in practices of predicting criminal behaviour through machine learning in ethical ways [1]; for example, how to reduce bias while maintaining accuracy. This is far from fundamentally questioning for which purpose we want to operationalise ML algorithms for; should we use them to predict criminal behaviour or rather to diagnose it, intervene on it and most importantly, to better understand it? Each approach comes with a different method for risk assessment; prediction with regression while diagnosis with causal inference [2]. I argue that, if the purpose of the criminal justice system is to treat crime rather than forecast it and to monitor the effects on crime of its own interventions — whether they increase or reduce crime — , then focusing our ethical debates on prediction is to deceive ourselves on the wrong track. Let us have a look at the present situation.https://www.technologyreview.com/s/607955/inspecting-algorithms-for-bias/Continue reading "The ethics of algorithmic fairness"